
Objective
To create these fake bios, we’ll need to rely on 3rd party website which will help us in generating fake bios for us. There are numerous websites out there which will generate fake profiles for us. This is a feasible way to write thousands of fake bios in a very reasonable amount of time.
Required libraries
requestsallows us to access the webpage that we need to scrapetimewill be needed in order to wait between webpage refreshesrefor regextqdmis only needed as a loading bar for our sake (optional)bs4is needed in order to use BeautifulSoupseleniumto stimulate click eventspandasto create dataframepickleto serialize objects
Code
Importing required libraries
import re
import time
import requests
import pandas as pd
import _pickle as pickle
from selenium import webdriver
from bs4 import BeautifulSoup as bs
# from tqdm import tqdm_notebook as tqdm
from tqdm.notebook import tqdm
from selenium.webdriver.common.keys import Keys
URL of website for scraping
URL = "https://www.character-generator.org.uk/bio/"
# Initialise with empty list
biolist = []
name_list = []
age_list = []
# launch WebDriver instance
driver = webdriver.Chrome()
# launch website
driver.get(URL)
Scrapping code may vary w.r.t website we choose
# find required element and perform action
driver.find_element_by_id('fill_all').click()
driver.find_element_by_id('quick_submit').click()
# wait for reponse
time.sleep(2)
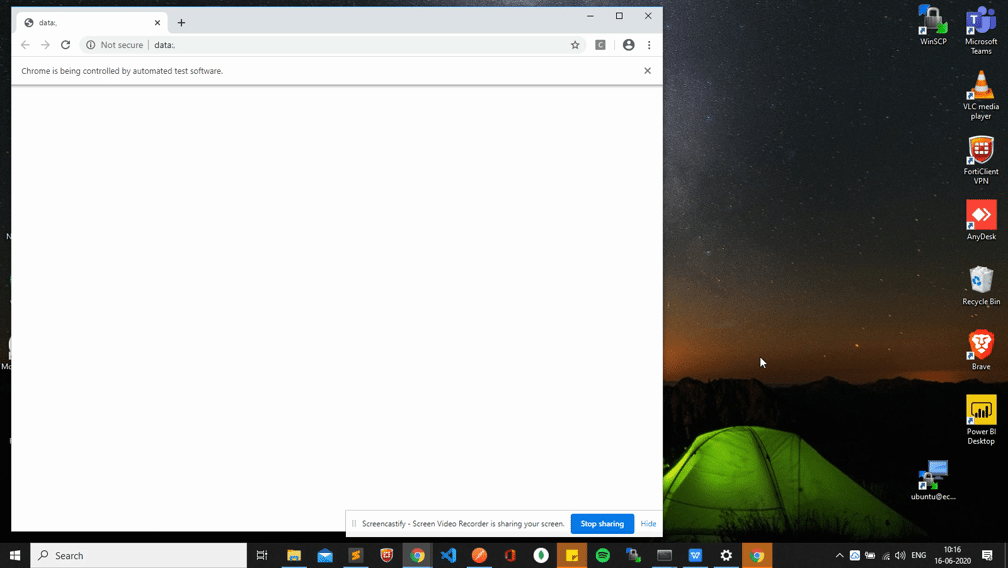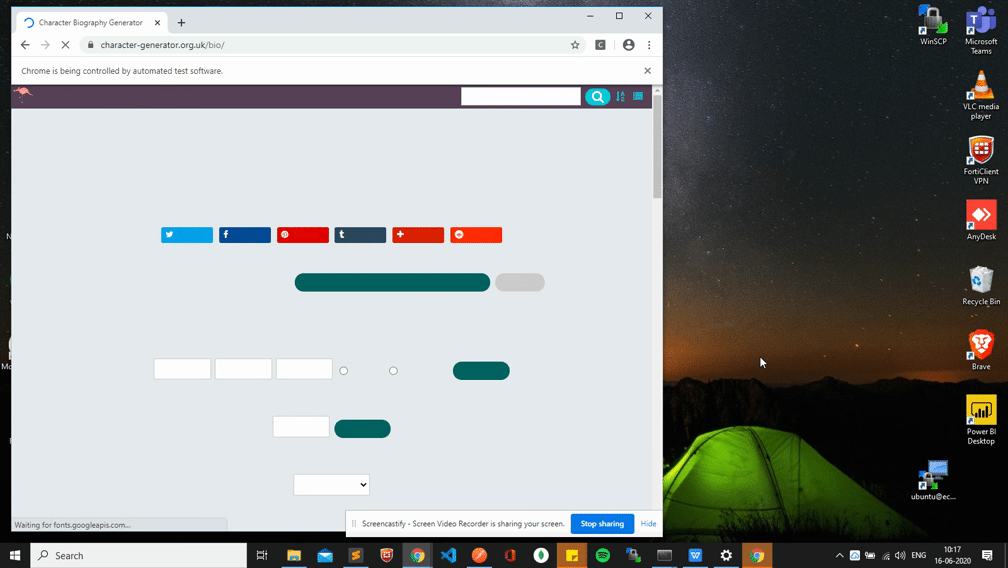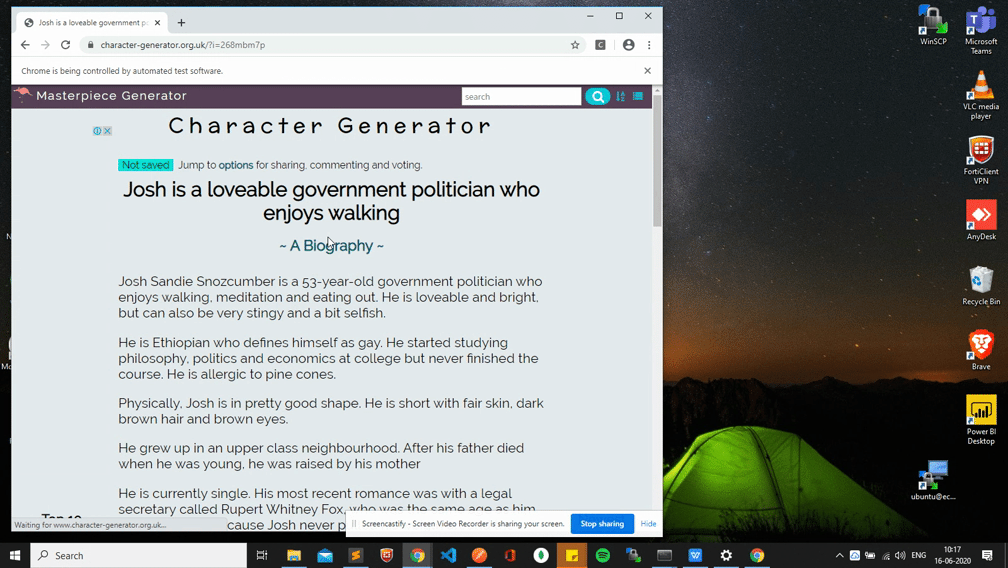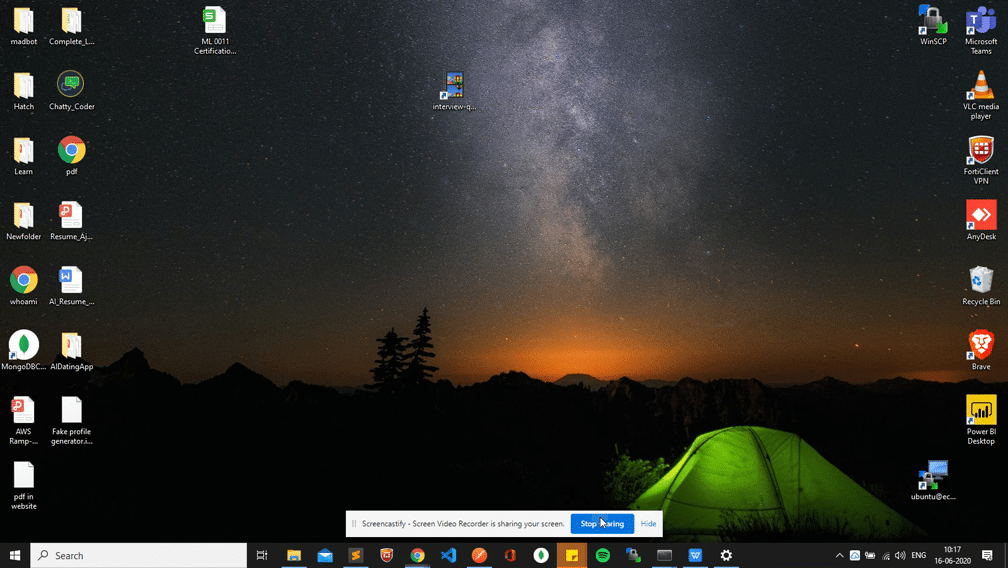
In my case url was changing after bios generation, so we need to get the updated url for further work
# get new url
url = driver.current_url
#get contents from url
page = requests.get(url)
Using request we get the contents of webpage in bytes format
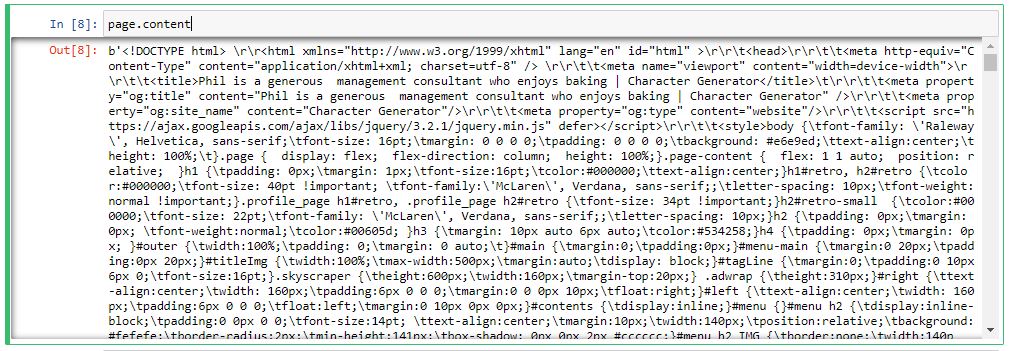
soup = bs(page.content)
USing Beautifulsoup, we parse content of webpage and get data into html format
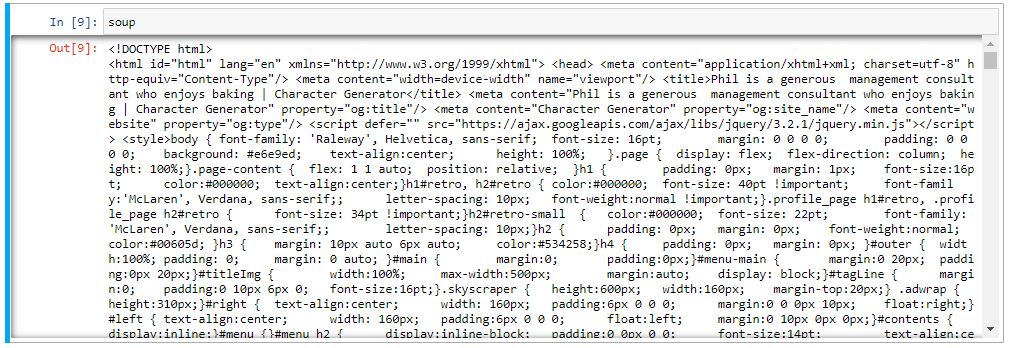
Then using find method we try to find particular element from html page e.g. div tag, its class name, <p> i.e. paragraph tag from html where our actual text strings are present. We can easily find these tags of any website by right click on that webpage and in option select Inspect.
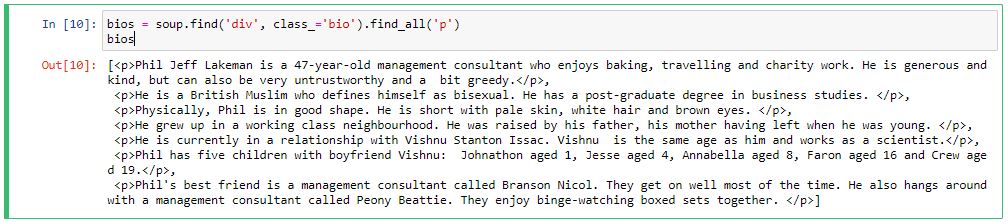
# Getting the bios
bios = soup.find('div', class_='bio').find_all('p')
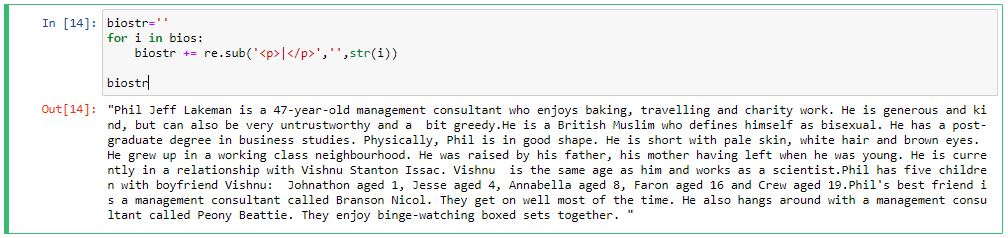
using regular expresion we removed <p>,</p> tags from our data and converted it into python string
biostr=''
for i in bios:
biostr += re.sub('<p>|</p>','',str(i))
This step could be optional step, uptil now we are able to collect whole bios containing all required information for any profile
Since we had a fix format of data, it was easy to capture from raw data
name First three word were name
age Only numeric value present in first sentence of data was user’s age
In similar way, we could capture a lot of information using regex
# To collect name, age from first string
name, age = ' '.join(biostr.split('.')[0].split(' ')[0:3]), int(re.findall("\d+", biostr.split('.')[0])[0])

After every loop will push new data into respective list
biolist.append(biostr)
name_list.append(name)
age_list.append(age)
This is must step to close the window of browser after finishing scraping task
driver.close()
Finally, zip all three lists and create a new dataframe
profile = pd.DataFrame(zip(name_list, age_list, biolist), columns=['name','age','bios'])
In this format we will be getting our data

Now we can serialise datframe object using pickle for future use
with open("bios_data.pkl", "wb") as fp:
pickle.dump(profile, fp)